
图像处理与计算机图形学关系
### 1.计算机视觉,计算机图形学和图像处理的区别与联系
从输入输出角度看
(1)区别
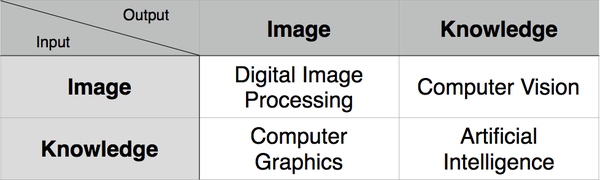
Computer Graphics,简称 CG 。输入的是对虚拟场景的描述,通常为多边形数组,而每个多边形由三个顶点组成,每个顶点包括三维坐标、贴图坐标、rgb 颜色等。输出的是图像,即二维像素数组。
Computer Vision,简称 CV。输入的是图像或图像序列,通常来自相机、摄像头或视频文件。输出的是对于图像序列对应的真实世界的理解,比如检测人脸、识别车牌。
Digital Image Processing,简称 DIP。输入的是图像,输出的也是图像。Photoshop 中对一副图像应用滤镜就是典型的一种图像处理。常见操作有模糊、灰度化、增强对比度等。
(2)联系
CG 中也会用到 DIP,现今的三维游戏为了增加表现力都会叠加全屏的后期特效,原理就是 DIP,只是将计算量放在了显卡端。
CV 更是大量依赖 DIP 来打杂活,比如对需要识别的照片进行预处理。
最后还要提到近年来的热点——增强现实(AR),它既需要 CG,又需要 CV,当然也不会漏掉 DIP。它用 DIP 进行预处理,用 CV 进行跟踪物体的识别与姿态获取,用 CG 进行虚拟三维物体的叠加。
(3)图解
这里还有一张图,简明地表达了CV、CG、DIP和AI的区别和联系。 区别和联系
2. 从问题本身看
(1)区别
| 从问题本身来说,这三者主要以两类问题区分:是根据状态模拟观测环境,还是根据观测的环境来推测状态。假设观测是Z,状态是X:Computer Graphics是一个Forwad Problem (Z | X): 给你光源的位置,物体形状,物体表面信息,你如何根据已有的变量的状态模拟出一个环境出来。 |
| Computer Vision正好相反,是一个Inverse Problem (X | Z):你所有能得到的都是观测信息(measurements), 根据得到的每一个Pixel的信息(颜色,深度),我要来估计物体环境的特征和状态出来,比如物体运动(Tracking),三维结构(SFM),物体类别(Classification and Segmentation)等等。 |
对于Image Processing来说,它恰好介于两者之间,两种问题都有。但对于State-of-art的研究来说,Image Processing更偏于Computer Vision, 或者看上去更像Computer Vision的子类。尽管这三类研究中,随着CV领域的不断进步,以及越来越高级相机传感器出现(Depth Camera, Event Camera),很多算法都被互相用到,但是从Motivation来看,并没有太大变化。
(2)联系
得益于这几个领域的共同进步,所以你能看到Graphics和Computer Vision现在出现越来越多的交集。如果根据观测量(图片),Computer Vision可以越来越准确的估计出越来越多的变量,那么这些变量套到Graphics算法中,就可以模拟出一个跟真实环境一样的场景出来。
与此同时,Graphics需要构建更真实的场景,也希望能够将变量更加接机与实际,或者通过算法估计出来,这就引入了Vision的动机。这也是近年来三维重建算法,同时大量发表在Graphics和Vision的会议的原因。随着CV从2D向3D发展,以后两者的交集会越来越大,除了learning以外的其他很多问题融合并到一个领域我也不会奇怪。
3. 图像处理
3.1 hough变换原理
y = kx+b直线在(x,y)坐标和(k,b)坐标中,都是线性的,而在后者中可以看到前者的不同形态,有对应关系.所以可以检测出直线.
通过限制(k,b)的定义域,可以处理相应的直线检测.
y = cos@/sim@ * x + r/sin@
参考: